Learning Cost Function Through Inverse Reinforcement Learning.
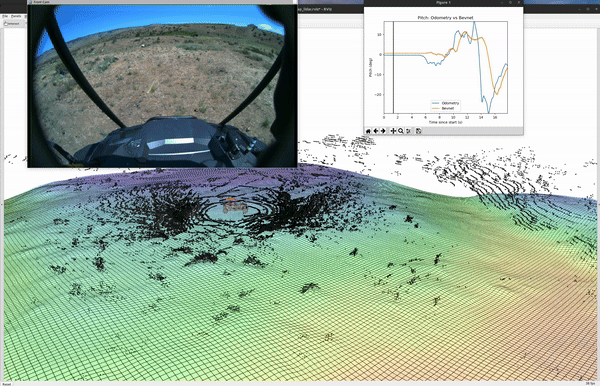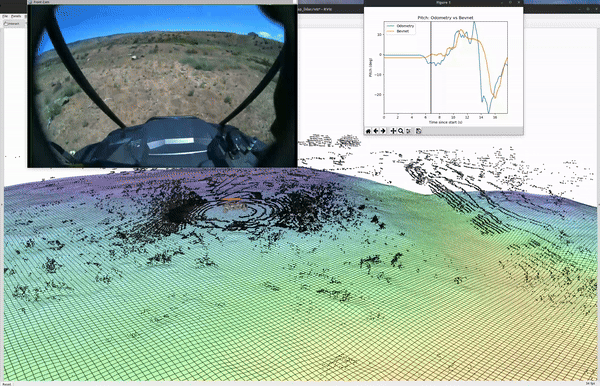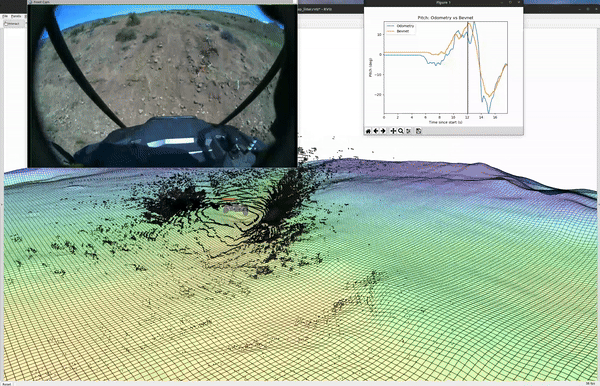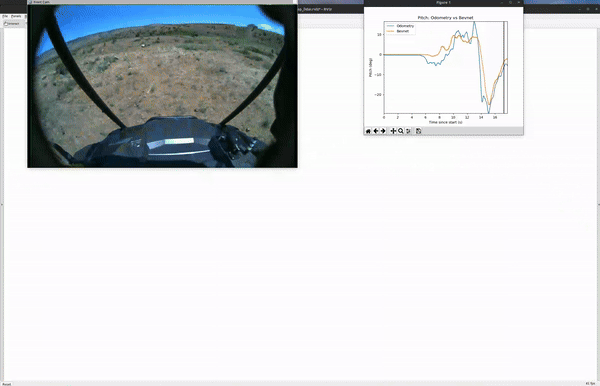

.png)
Project information
- Navigation through unstructured environments remains a task in which humans are substantially more competent than robots.
- We target the fundamental issue to robotics, perception-control relationship. We are Developing end-to-end policies for robotic applications that prioritize objective-driven representations, enabling robust decision-making under uncertain and incomplete environmental conditions.
- Approach:
- Address fundamentally poor perception, dynamics, and unobservability in unstructured environments.
- Algorithmically tune MPC parameters to compensate for perception through end-to-end learning
- Learn components of the objective that are difficult to manually define. Ex: how to behave when there is no sensor information from the ground
- Integrate pereption into POMDP-based planning, leveraging imitation learning without assuming convergence to an underlying MDP.